maf入門¶
この文書ではmafを使いはじめようとしている人のために、mafとは何で、何のためにあって、どうやって使うのかを解説します。 その途中、ビルドツールを用いた実験計画の記述という、mafを使う上で必須となる考え方を紹介します。 具体的な使い方を解説する上で、ビルドツールwafの使い方については既知として進めます。
これを読む皆様に快適な実験生活が訪れることを願っています!
mafとは¶
maf はコンピュータプログラムを用いた実験を記述するための環境です。 特に実験対象となるプログラムに設定やパラメータがあり、その設定・パラメータを様々な値に変えたときの実験結果を管理・処理・比較する場合に有用です。
mafは当初、機械学習の実験を新たに始めるときに役立つツール集という位置付けで作り始めました。 現在は機械学習に依らず、ソフトウェアやアルゴリズムの比較実験・検証に広く用いることができます。
mafの目的¶
ソフトウェアの実験はたとえば以下の手順で進みます。
- 設定を列挙する
- 各設定のもとでプログラムを走らせ、結果を書き出す
- 得られた結果を集約する
- 集約された結果を可視化する
実験を回す方法は大きく分けて二種類あります。
- 手で設定を書いて実験を回し、設定を書き換えて実験を回す。これを繰り返す。
- 設定を生成して実験を回すスクリプトを書く。
前者のやり方は、はじめの開発コストが小さいという点で魅力的です。 しかし設定に関する網羅的な実験には向きませんし、試行錯誤の過程で何を試したのかが残りにくいという欠点があります。
後者ではこれらの問題点を克服することができます。 ただし、すべての実験を再現できるようにスクリプトを書いた場合、設定を一部変更して再実験した場合に、実験全体をやり直さないといけないという問題があります。 (他の人も経験があると信じていますが)maf開発者がよくやってしまっていたのは、再実験に必要ない部分をその都度コメントアウトするという方法です。 これで再実験の効率については問題がなくなりますが、実験の複雑さに対してスケールせず、いつか破綻します。 また、実験が複雑になり、中間データが増えてくると、その管理が難しくなっていきます。
ここで挙げたそれぞれの方法における問題点は、実験の(想定以上の)複雑さに起因しています。 mafはこういった 実験の複雑さを隠蔽する ためにあります。
waf¶
mafは waf というツールの拡張として提供されます。 wafはPythonで書かれたビルドツールで、拡張性の高さが特徴です。
ビルドツールは、ソースコードを実行可能なプログラムに変換する処理を抽象化して記述するためのソフトウェアです。 入力ファイルと出力ファイルの依存関係を記述すると、ビルドツールがこれを解析して適切な順序で出力ファイルを生成します。 例えば Figure 1 のように、ソースファイルから実行可能ファイルやライブラリを作ります。
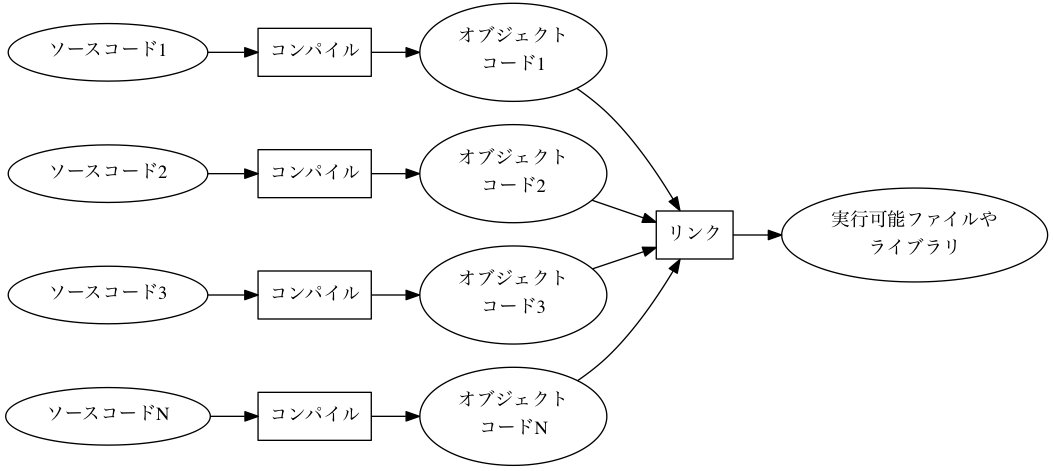
Figure 1: ソースコードの単純なビルド例。
wafは様々な言語処理系に対応したビルドツールで、依存関係をDSLのような見た目をしたPythonコードで記述することができるのが特徴です。 wafの詳細については 本家サイト にドキュメントが整備されています (waf bookとAPI doc)。 使用例としては、例えば Jubatus を参照してください。
wafを含め、多くのビルドツールはソースコードのコンパイル・リンク以外にも、任意のファイル変換に用いることができます。 例えば、設定ファイルを読み込んで実験を行い結果を出力するプログラムがあったとします。 このプログラムは、設定ファイルから実験結果を生成する変換器と見なすことができます。 図にすると Figure 2 のようになります。
すると、実験計画をビルドツール上に記述することができることに気づきます。 実際、Figure 2 は Figure 1 にとてもよく似ています。 wafを用いると、Figure 2 のような実験も書くことができます。 mafは、このようなwafを用いた実験をより書きやすくするためのwaf拡張です。
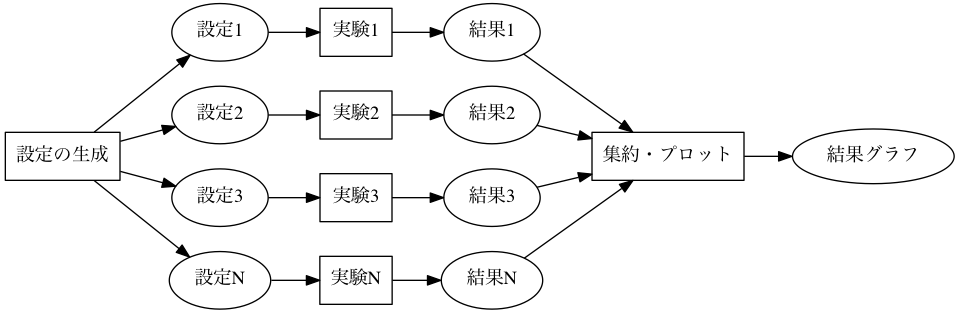
Figure 2: ビルドツールを参考にした実験の流れの例。
ここからは、wafの(言語に依らない)ごく基本的な使い方は既知のものとして進めます。 たとえば、以下のwscriptが読めれば十分です。 このwscriptは、 hoge.txt と fuga.txt に文字列を書き込み、それらを結合したファイル concat.txt を生成します。 Figure 3 が対応するビルド図を示します。
def configure(conf):
pass
def build(bld):
bld(target='hoge.txt', rule='echo "hoge" > ${TGT}')
bld(target='fuga.txt', rule='echo "fuga" > ${TGT}')
bld(source='hoge.txt fuga.txt', target='concat.txt',
rule='cat ${SRC} > ${TGT}')

Figure 3: wafによるファイル処理の例。
実験の際には echo や cat などの部分が、一つの設定に対する実験プログラムや結果の集約処理に変わると思ってください。 次節以降で、より具体的にwafを用いた実験について見ていきます。
wafを用いた実験例¶
実験設定 データが書かれたファイル input.txt を入力とする実験プログラム do_experiment に対する実験を行います。 do_experiment は以下のような実行時引数を取るとします。
$ do_experiment input.txt <parameter> > output.txt
このとき、以下のような実験 (Figure 4) を行いたいとします。
$ do_experiment input.txt 1 > output1.txt
$ do_experiment input.txt 2 > output2.txt
$ do_experiment input.txt 3 > output3.txt
$ do_experiment input.txt 4 > output4.txt
$ do_experiment input.txt 5 > output5.txt
$
$ plot these outputs
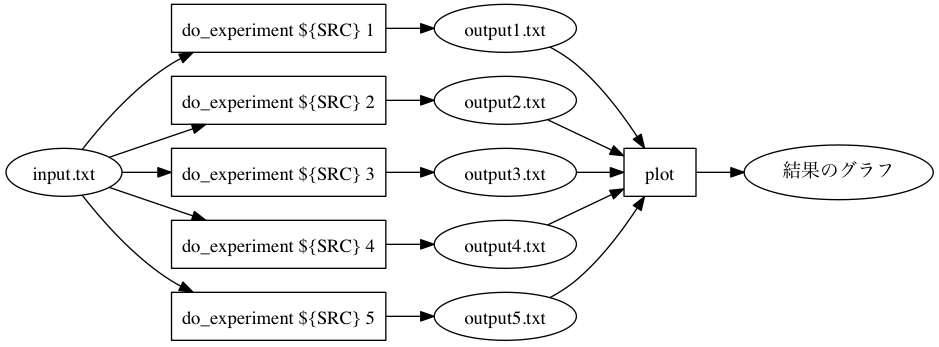
Figure 4: wafによる実験のビルド図。
最後のplotについては何か追加でスクリプトを書くものとします。
wafに移植 この実験をwaf上で記述すると、次のようになります。
def build(bld):
for i in range(1, 6):
bld(source='input.txt',
target='output%s.txt' % i,
rule='do_experiment ${SRC} %s > ${TGT}' % i)
bld(source=['output%s.txt' % i for i in range(1, 6)],
target='plot.png',
rule=plot)
def plot(task):
"""wafのタスクオブジェクトを受け取ってプロットするスクリプト。
入力ファイルにはtask.inputs[i]で、出力ファイルにはtask.outputs[0]でアクセスできる。
"""
...
bld は関数呼び出しのできるオブジェクトで、関数呼び出しに source, target, rule を指定することでファイルの依存関係と生成ルールを記述します。 wafはPythonが直接記述できるのが特徴で、このようにループも使えます。 しかし、この例では中間ファイルとなる outputN.txt は自分で名前をつけて管理しています。 パラメータの範囲が変わるだけならループ部分を書き換えるだけですが、例えばパラメータが増える場合には、ファイル名の作り方を変えないといけません。
mafを用いた実験例¶
上のwafを用いた例は、mafを用いた場合には以下のように書き換えられます。
def build(bld):
bld(source='input.txt',
target='output',
parameters=[{'parameter': i} for i in range(1, 6)],
rule='do_experiment ${SRC} ${parameter} > ${TGT}')
bld(source='output',
target='plot.png',
for_each=[],
rule=plot)
def plot(task):
... # 上の場合と同じ
wafの場合とは以下の点で異なっています。
- for 文の位置が変わりました。 bld をパラメータの数だけ呼び出すのではなく、パラメータを並べた配列を parameters として渡します。 このように書くだけで、各パラメータごとに別々の依存関係を作り出し、同じ数の出力ファイルができます。 出力は全体をまとめて output という名前で管理できます。
- プロットの部分が変わりました。 ここではもはや、パラメータの組合せを知らなくても書けます。 for_each=[] についてはここでは触れませんが、 output に含まれるファイル全部に対して一つの出力ファイルを生成することを意味しています。
mafによる上記の実験例を図に表すと Figure 5 のようになります。 パラメータの数だけ操作と出力ファイルができますが、その管理をmafが自動で行っている様子がわかります。 ユーザーが触るのはパラメータが違うノードを束ねたもの(図において色がけした塊)だけです。
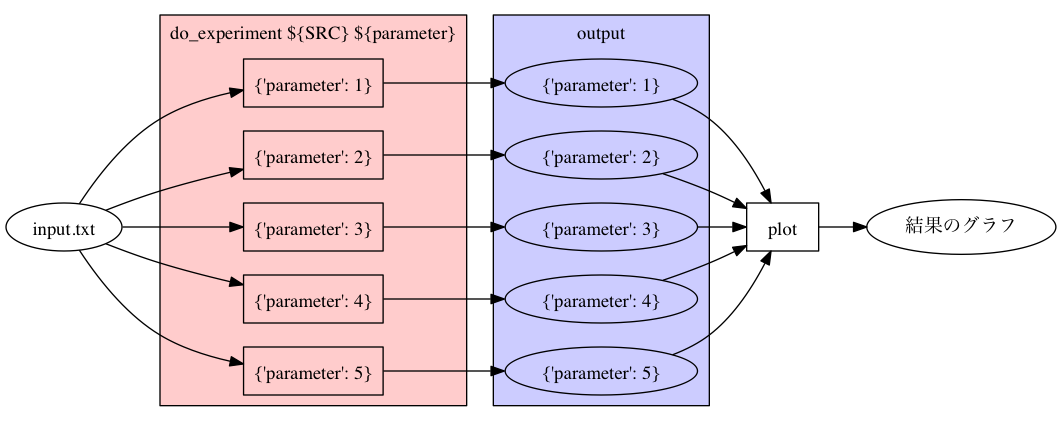
Figure 5: mafによる実験のビルド図。
重要な点は、パラメータの組合せを一箇所だけに書けるようになったことです。 パラメータについて変更を加えたい場合、この一箇所だけを変更すれば他の部分がそれに追随します。
この章ではビルドツール、そしてその拡張であるmafを用いた実験計画の入り口を垣間見ました。 mafのエッセンスはすでに上記の例に現れています。
次章では実際にmafを用いて実験を行うために必要な知識、および便利な機能を紹介していきます。 mafにおける諸概念の詳細な定義や挙動、および各機能の仕様についてはAPIドキュメントを参照してください。